Multi Modal Ai Learning System
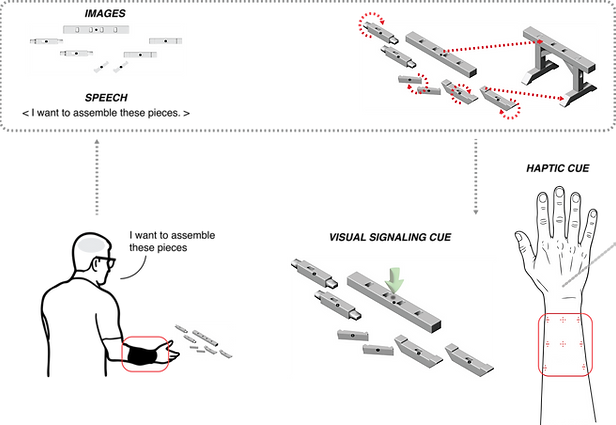
My current, ongoing thesis project develops a visuohaptic system that uses a vision–language model to
break down novel assemblies into discrete steps. These steps are delivered through AR visual overlays on
a headset and spatial rotation cues from a wearable haptic band that provides vibration feedback, to guide
users through the assembly process.
Date: 2025
Project Type: Thesis Research
Keywords: Haptics, AR, Assembly
Advisors: Takehiko Nagakura, Randall Davis, Skylar Tibbits

Motivation
As large language models (LLMs) and other accessible, interactive AI modalities become increasingly common, a central question emerges: are multimodal, embodied AI interfaces more effective for learning than traditional text-based interaction?
Most LLM systems today operate through chat-style interfaces, where users provide text input and receive text output. This research investigates an alternative interaction paradigm: multisensory learning systems that coordinate visual, haptic, and auditory cues to support spatial cognition and skill acquisition in tasks such as assembly and navigation. By distributing guidance across multiple sensory channels, the work examines whether multimodal interaction can improve comprehension, reduce cognitive load, and increase task performance relative to conventional text-first AI interfaces.
Approach

Sleeve Design
Iteration 1


Using a series of different assembly meshes, some drawn from the ASAP research of the Computation Design Group at MIT CSAIL, this beam requires multiple steps and a solid overall understanding in order to determine its assembly.
